随着科技的进步和数据科学的发展,基于历史数据分析与统计模型的比赛结果预测方法成为了各类赛事分析中重要的工具。特别是在体育、选举、股市等领域,如何通过精确的统计建模与数据分析对未来的比赛结果进行预测,已成为研究者和从业者关注的焦点。本篇文章将探讨基于历史数据分析与统计模型的比赛结果精准预测方法,首先简要概述该方法的发展和应用背景;随后,文章将从四个方面对该方法进行详细阐述:历史数据的收集与处理、统计模型的选择与应用、预测模型的优化与调整、以及预测结果的验证与评估。最后,结合本文内容对基于历史数据分析与统计模型的比赛结果预测方法进行总结与展望,提出未来发展的可能方向。
历史数据是比赛结果预测的基础。要建立一个有效的预测模型,首先需要收集大量的历史比赛数据,包括参赛队伍、选手的表现数据、比赛的环境条件、战术部署等信息。这些数据为模型提供了初步的分析基础。尤其在体育比赛中,参赛者的身体状态、过往表现以及与对手的对抗历史都能为预测提供有力的支持。
数据的质量直接影响预测结果的准确性。在数据收集的过程中,保证数据的完整性、准确性以及一致性至关重要。为了保证数据的高质量,通常需要通过自动化工具和数据清洗技术来剔除噪声数据,填补缺失值,并对异常数据进行调整。对于不同类型的比赛,数据的处理方式也有所不同。例如,在足球比赛中,可能需要对球员的伤病记录、球队的战术安排进行分析;而在选举预测中,则更多关注选民的历史投票数据与社会经济因素。
此外,数据的标准化处理也是不可忽视的环节。由于不同比赛的评估指标差异较大,统一的数据标准化处理有助于消除不同数据维度间的影响,使得不同来源的数据能在同一框架下进行比较和分析。通过合理的预处理步骤,可以最大限度地提高模型的预测精度。
在收集并处理好历史数据之后,选择适合的统计模型是进行比赛结果预测的关键一步。目前常用的统计模型包括回归模型、时间序列分析模型、机器学习模型等。在实际应用中,选择何种模型往往取决于数据的特性以及问题的具体需求。
回归分析模型广泛应用于比赛结果预测中,特别是在需要量化某些关键因素对比赛结果影响时。例如,在篮球比赛中,可以通过回归分析来研究投篮命中率、篮板球数等指标对比赛胜负的影响。线性回归、逻辑回归等方法较为常见,但也有时会涉及更复杂的非线性回归模型,以应对更复杂的因果关系。
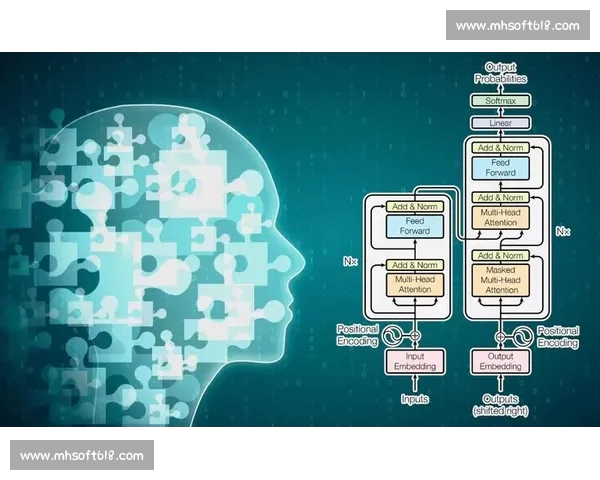
除了回归模型,时间序列分析模型在一些具有时间依赖性的赛事中也得到广泛应用。例如,股票市场或体育赛事中,某些因素(如球员状态或股市走势)往往呈现出时序性,这时使用时间序列模型进行预测,能够较好地捕捉到数据中的趋势和周期性变化。此外,机器学习技术也在比赛结果预测中逐渐取得突破,尤其是决策树、支持向量机和深度学习等算法,它们通过数据的自学习能力,可以在大数据环境下有效地进行高维度、多样化的预测。
即便使用了合适的统计模型,如何通过优化和调整模型以达到更高的预测精度,依然是一个重要的课题。在实际操作中,模型的优化通常涉及参数调节、特征选择和模型融合等多个环节。
参数调节是优化模型的重要步骤之一。在很多统计模型中,参数的选择对模型的预测效果有着至关重要的影响。例如,在支持向量机模型中,核函数的选择和惩罚系数的设置会直接影响模型的准确度。通过交叉验证和网格搜索等技术,能够在大量参数空间中找到最合适的组合,从而提升模型性能。
特征选择则是提高模型效率的另一重要策略。特征选择通过挑选出最能影响比赛结果的因素,去除无关或冗余的变量,从而减少数据的复杂度,提高模型的泛化能力。采用主成分分析(PCA)、L1正则化等方法进行特征选择,有助于更好地捕捉数据中的重要信息。
在多个模型相结合的情况下,模型融合也是提升预测精度的重要手段。通过将不同类型的预测模型进行加权组合,可以弥补单一模型的局限性,进一步提高预测的可靠性。例如,结合回归模型和机器学习模型的集成方法,能够综合利用两者的优点,在复杂的数据环境中取得更好的预测结果。
在进行比赛结果预测时,验证与评估模型的效果是至关重要的一步。通过评估,能够了解模型的实际表现,并根据评估结果进行调整与优化。常见的评估指标包括准确率、召回率、F1分数等,这些指标能够全面反映模型的优缺点。
准确率是最直观的评估标准之一,但仅仅依靠准确率有时并不能全面反映模型的性能。例如,在一些不平衡数据集上,模型可能会偏向预测多数类,而忽视少数类,这时召回率和F1分数就显得尤为重要。通过综合使用这些指标,可以全面了解模型的预测能力。
此外,交叉验证也是验证模型的重要方法之一。通过将数据集划分为多个子集,并在不同的子集上进行训练和验证,能够更有效地避免过拟合问题,从而提高模型的泛化能力。交叉验证结果能够提供更稳定的评估,帮助研究人员在不同场景下评估模型的实际应用效果。
总结:
本文详细探讨了基于历史数据分析与统计模型的比赛结果预测方法,涵盖了从数据收集到模型优化与评估的全过程。通过对历史数据的收集与处理,研究者可以为模型提供有效的输入;通过选择合适的统计模型,结合回归分析、时间序列分析与机器学习算法,可以提高预测的准确性;通过优化模型参数与特征选择,可以进一步提升预测精度;通过模型的验证与评估,最终确保预测结果的可靠性。所有这些步骤的有机结合,为比赛结果预测提供了强有力的支持。
星空·体育中国综合,星空·综合(中国),星空综合体育中国,星空综合·(中国)体育未来,随着数据科学和人工智能的不断发展,基于历史数据分析与统计模型的比赛结果预测方法将不断得到改进和创新。尤其是在大数据环境下,如何处理海量复杂数据,如何利用深度学习等先进技术提升预测精度,将成为未来研究的重点方向。此外,跨领域的联合分析也将成为比赛结果预测的新趋势,为更多领域的预测提供参考和借鉴。